2편에서 만든 백테스트 위에 한 층 더 올린 — Grid Search로 룰을 자동 탐색하는 모듈. 사용자가 “어떤 RSI threshold가 좋은가” 같은 정답 없는 질문을 매번 던지지 않아도 되게.
문제
룰을 손으로 짜면 두 가지를 동시에 맞춰야 한다.
- factor 선택 — RSI? SMA 이격도? 거래량 배수? 어떤 게 이 universe에 잘 먹나?
- threshold 결정 —
RSI < 30이 좋나,< 25가 좋나,< 35가 좋나?
한 룰씩 손으로 백테스트 돌려보면 얕고 우연한 결과에 빠지기 쉽다. 그래서 grid를 자동으로 깔고 모든 조합을 평가해, 데이터 분할 기반 1차 과적합 필터를 통과한 것만 상위 N개로 추천하기로 했다.
Grid 구성
3차원 grid: factor × op × threshold.
# service/backtest/discover.py
DEFAULT_FACTORS = ["rsi_14", "vol_ratio_20d", "return_5d", "price_vs_sma50"]
DEFAULT_OPS = ["<", ">"]
DEFAULT_PERCENTILES = [0.1, 0.3, 0.5, 0.7, 0.9]threshold는 절대값이 아니라 universe 내부 분포의 percentile로 잡는다. RSI 30 같은 절대 기준은 universe별로 의미가 다르니 (KOSPI 200과 R3000의 RSI 분포가 다름), 동일한 룰이라도 본인이 돌리는 universe 안에서의 상대 위치로 grid를 깐다.
def _factor_quantiles(symbols, factor, percentiles):
query = f"SELECT {factor} AS v FROM factors WHERE symbol IN ({...})"
df = pd.read_sql(query, conn, params=params)
return df["v"].quantile(percentiles).tolist()단일 절(n_clauses=1)이면 4 factors × 2 ops × 5 percentiles = 40개 룰. 2-clause AND 조합은 다른 factor끼리만 (같은 factor AND는 의미 없음) 묶어서 수백수천 개로 폭발한다. 모두 평가한다.
학습 7년 / 검증 3년 — 1차 과적합 필터
기간을 7:3으로 split해 두 번 평가한다.
def _split_train_test(start_date, end_date, train_ratio=0.7):
# 디폴트 10년 — 약세장(2018, 2020, 2022)·강세장 모두 포함
end_dt = ...
start_dt = end_dt - 10년
split_day = start_dt + (total_days * train_ratio)
return train_start, train_end, test_start, test_end
# 각 조합 — train·test 두 번 백테스트
train_m = fast_backtest(train_cache, clauses, ...)
test_m = fast_backtest(test_cache, clauses, ...)핵심은 정렬 key다.
def _sort_key(r):
both_positive = (
(1 if r["train_alpha"] > 0 else 0)
+ (1 if r["test_alpha"] > 0 else 0)
)
return (
both_positive, # 1순위
(r["train_alpha"] + r["test_alpha"]) / 2, # 2순위
(r["train_sharpe"] + r["test_sharpe"]) / 2, # 3순위
)- 1순위 — 양 기간 모두 alpha1 양수: 학습에서만 좋고 검증에서 망한 룰은 자동으로 뒤로 밀린다. 흔한 과적합2 패턴.
- 2순위 — alpha 평균: 양수 통과한 것들 사이에선 벤치마크 초과수익이 큰 순.
- 3순위 — sharpe3 평균: 동률일 때만.
이 정렬 덕에 화면에 뜨는 추천 룰은 학습·검증 양쪽에서 시장을 이긴 룰이고, “지난 5년 best는 결국 fluke” 함정을 1차로 피한다.
⚠️ 그래도 미래는 보장되지 않는다. 양 기간 통과한 룰도 실전에선 무너질 수 있다. discover는 “더 나쁜 룰 거르기”지 “이기는 룰 찾기”가 아니다.
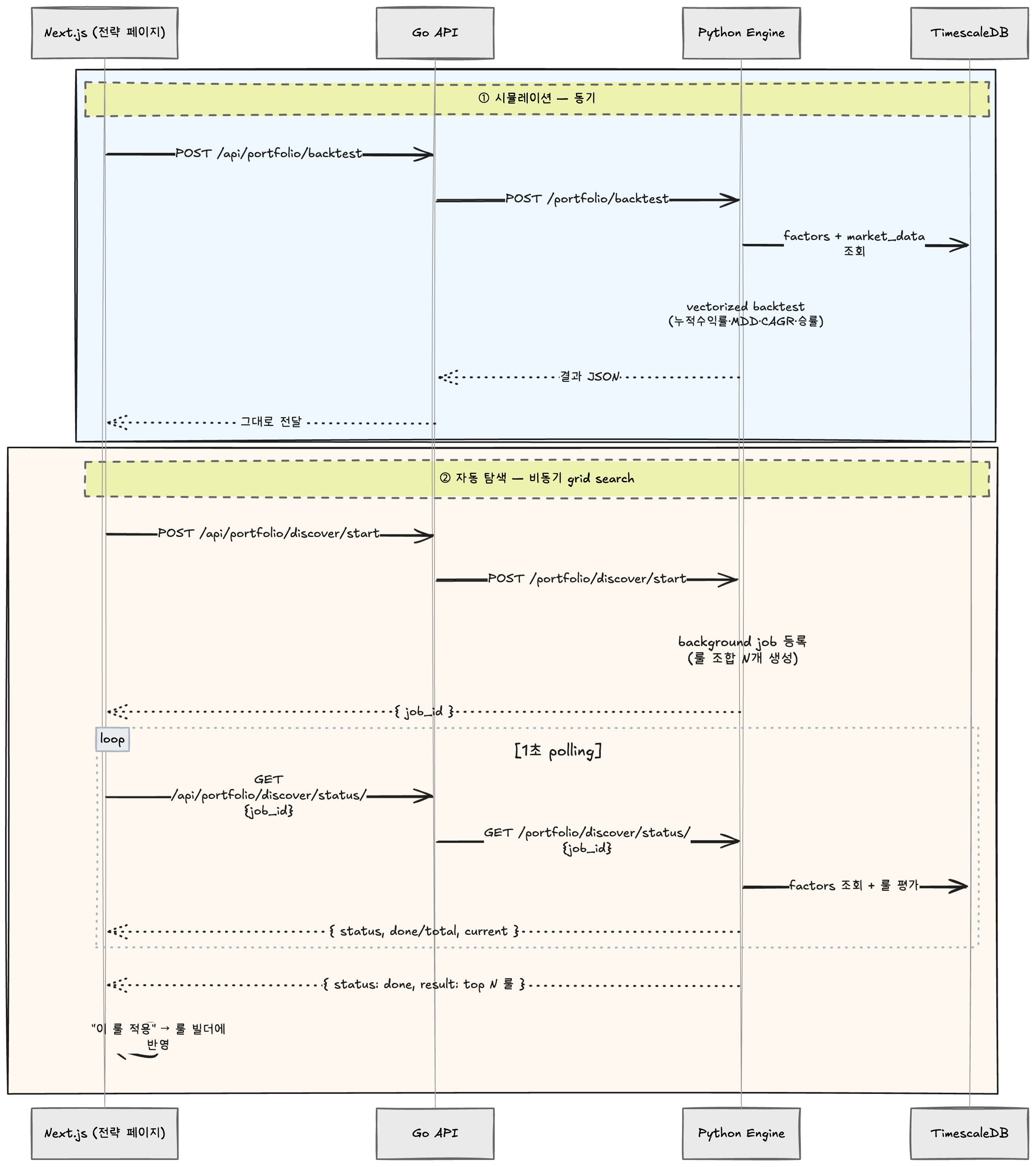
비동기 + 진행률 polling
40개 룰이면 10초 안쪽이지만 2-clause 수백~수천 조합은 분 단위. 동기 응답으로 묶으면 브라우저 timeout 먹으니 비동기 job 패턴.
POST /discover→ 즉시job_id반환, 백그라운드에서 grid 평가 시작- 평가 루프 안에서
progress_cb(current, total, label)가 메모리 dict 갱신 - 프론트는
GET /discover/jobs/{id}로 polling — 진행률 + 마지막 평가한 룰 라벨 표시 - job 결과는 메모리에 30분 보존 — 다른 페이지 갔다 돌아와도 같은 id로 재조회
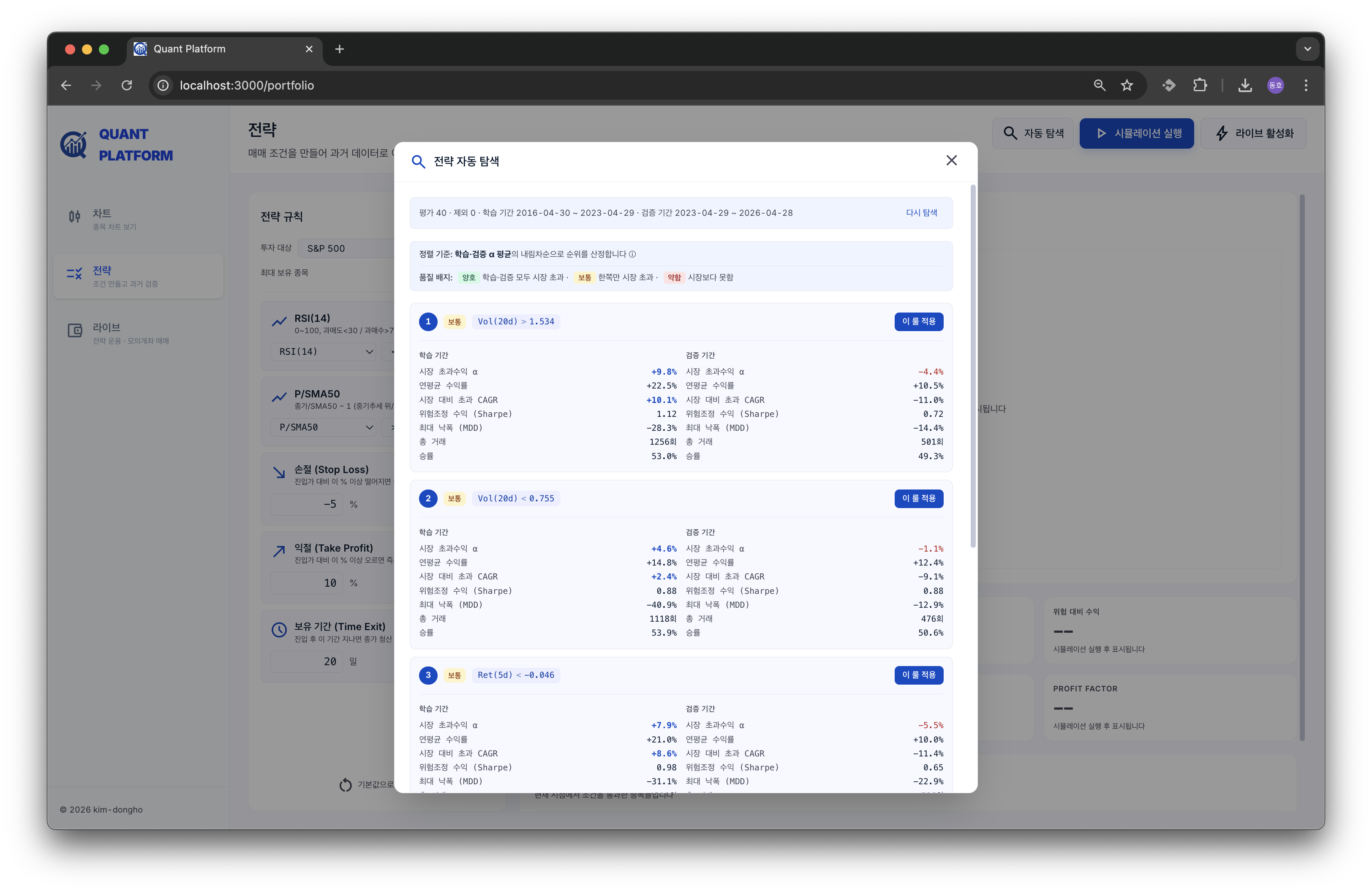
추천 카드 한 개에는 학습 / 검증 두 기간의 alpha · CAGR · MDD · Sharpe · 거래수 · 승률이 모두 노출되고, 우측에 양호 / 보통 / 약함 배지가 뜬다 (양 기간 통과 / 한 기간만 통과 / 둘 다 마이너스). “이 룰 적용” 한 번 누르면 그대로 전략 빌더로 들어간다.
회고
이 모듈을 만들면서 한 가지 명심하게 된 것.
Grid Search는 룰을 고르는 도구가 아니라 거르는 도구다.
수백 룰 중 best top 5만 봐도 우연히 좋아 보이는 게 항상 섞여있다. 7:3 split이 도움은 되지만 답은 아니고, 결국 “이 룰이 왜 통계적으로 의미 있을까”를 사람이 판단해야 한다. discover의 가치는 그 판단을 5개 정도로 좁혀준다는 데 있다.
다음 편은 검증된 룰을 KIS API 위에서 실제 매매로 돌리는 라이브 자동매매. 토큰·rate limit·동시호가 4가지 함정 얘기.
Footnotes
-
alpha (α) — 벤치마크 (예: 인덱스 ETF) 대비 초과수익. 벤치마크가 같은 기간에 +10%, 전략이 +13% 면 alpha = +3%. 시장 흐름에 묻히지 않는 전략의 고유 기여분 을 보는 지표. ↩
-
과적합 / overfitting — 모델이 학습 데이터의 패턴을 너무 잘 맞추는 바람에, 새로운 데이터에서는 오히려 성능이 떨어지는 현상. Grid Search 에서 “지난 N년 best” 가 미래에선 fluke 가 되는 가장 큰 원인. ↩
-
Sharpe ratio — (수익률 − 무위험 수익률) ÷ 변동성. 위험 대비 수익률. 같은 수익률이라도 변동성이 작으면 Sharpe 가 높다. 보통 1.0 이상이면 괜찮음, 2.0 이상이면 좋음으로 본다. ↩