1편에서 시스템 전체 구조를 봤다. 이번 편은 그 안에서 가장 핵심에 해당하는 백테스트 데이터 파이프라인 — 시세를 어떻게 적재하고, 팩터를 어떻게 미리 계산하고, 그 위에서 룰을 어떻게 빠르게 시뮬레이션하는지.
왜 precompute가 필요했나
처음엔 단순하게 OHLCV 10년치만 DB에 있고, 백테스트가 돌 때마다 RSI·SMA를 그 자리에서 계산하게 만들었다.
문제가 둘 있었다.
- 느림 — Grid Search 한 번이 수백~수천 룰 조합을 평가한다. 매번 raw OHLCV에서 RSI(14)·SMA(200)를 다시 돌리면 한 번 탐색에 수십 분이 깨졌다.
- 재현성 — 라이브 매매에서 “오늘의 후보”를 스크리닝할 때도 같은 팩터를 다시 계산해야 한다. 백테스트와 라이브가 각자 계산하면 미세한 차이가 누적되기 쉽다.
해법은 팩터를 별도 테이블에 미리 계산해 두는 것. 백테스트와 라이브가 같은 factors 테이블을 읽도록 통일했다.
데이터 — 한·미 자동 분기
미국은 yfinance, 한국은 FinanceDataReader. 호출자는 symbol 만 넘기고, 적재 함수가 형식으로 분기한다.
005930.KS→ KOSPI091990.KQ→ KOSDAQAAPL→ US
엔진이 외부 API에서 OHLCV를 받아 TimescaleDB에 적재하고, 적재 직후 곧장 팩터까지 자동 계산한다.
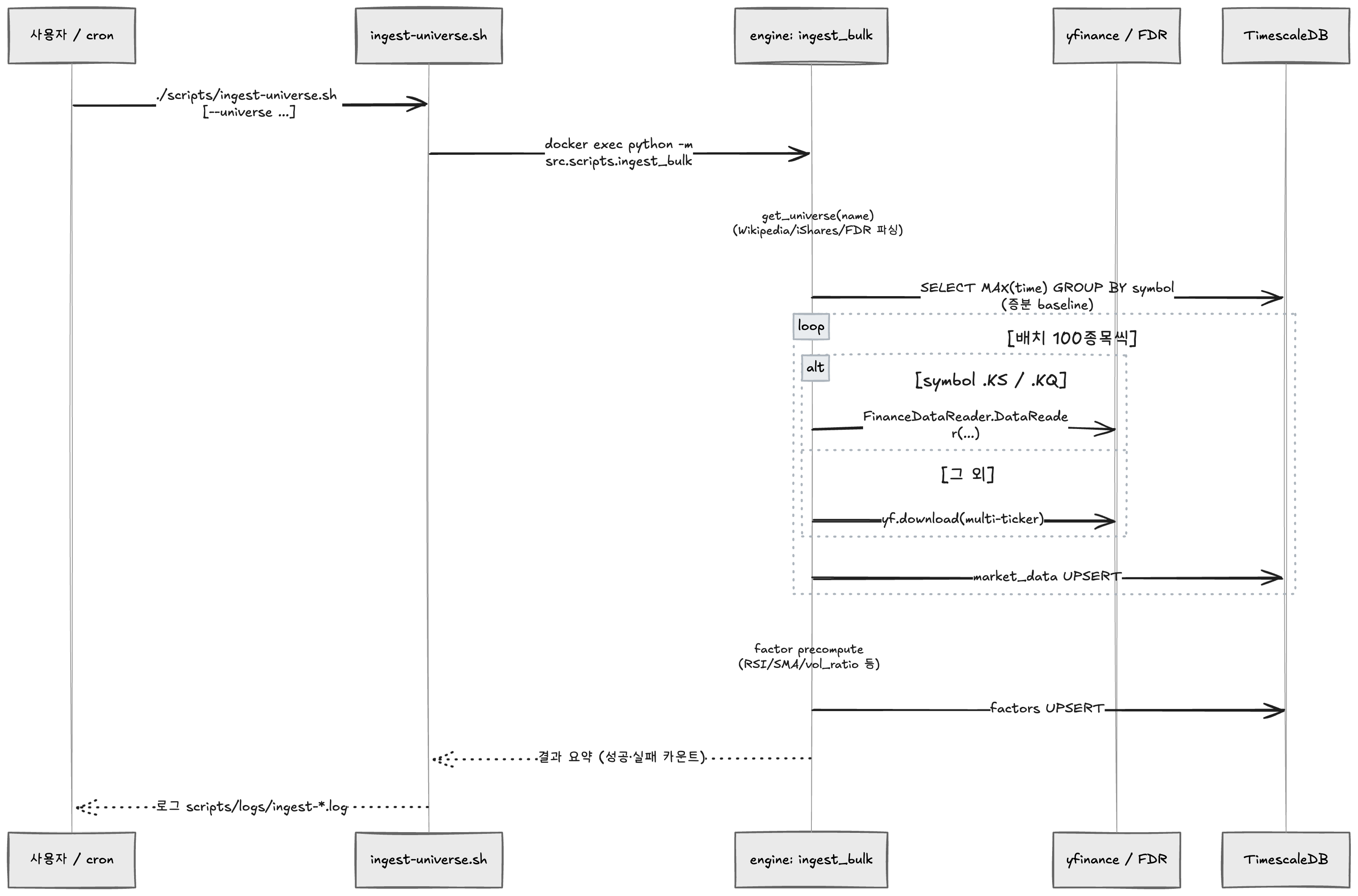
증분 적재가 핵심이다. 이미 있는 종목은 마지막 날짜 이후 봉만 받아오고, 없으면 10년치 bulk. 유니버스 9종 (sp500, russell3000, krx350, kospi200, kosdaq150 등) 을 한 스크립트로 돌린다.
TimescaleDB 스키마
3개 테이블만 보면 된다.
-- migrations/schema.sql
CREATE TABLE market_data (
time TIMESTAMPTZ NOT NULL,
symbol VARCHAR(20) NOT NULL,
open DOUBLE PRECISION,
high DOUBLE PRECISION,
low DOUBLE PRECISION,
close DOUBLE PRECISION,
volume BIGINT,
PRIMARY KEY (time, symbol)
);
CREATE INDEX ix_symbol_time_desc ON market_data (symbol, time DESC);
CREATE TABLE factors (
time TIMESTAMPTZ NOT NULL,
symbol VARCHAR(20) NOT NULL,
rsi_14 DOUBLE PRECISION,
sma_20 DOUBLE PRECISION,
sma_50 DOUBLE PRECISION,
sma_200 DOUBLE PRECISION,
vol_ratio_20d DOUBLE PRECISION,
return_5d DOUBLE PRECISION,
price_vs_sma20 DOUBLE PRECISION,
price_vs_sma50 DOUBLE PRECISION,
price_vs_sma200 DOUBLE PRECISION,
sma20_vs_sma50 DOUBLE PRECISION,
PRIMARY KEY (time, symbol)
);
CREATE INDEX ix_factors_symbol_time_desc ON factors (symbol, time DESC);(time, symbol) 복합 PK로 한 종목·한 시점의 봉이 단 1개임을 보장한다. (symbol, time DESC) 인덱스는 “가장 최근 N봉” 조회를 1ms 안쪽으로 잡아준다 — 종목 하나당 10년치 ≈ 2,500봉이라 인덱스 없이도 빠르긴 하지만, 다종목 join 시 차이가 크다.
라이브 전략 쪽엔 partial unique index1 하나가 더 있다.
-- 활성 전략은 동시에 1개만
CREATE UNIQUE INDEX ux_live_strategies_active
ON live_strategies ((TRUE)) WHERE is_active;
-- 한 전략 안에서 같은 심볼은 동시에 1개의 open trade만
CREATE UNIQUE INDEX ux_live_trades_open
ON live_trades (strategy_id, symbol) WHERE exit_date IS NULL;partial index의 WHERE 절이 도메인 제약을 그대로 데이터베이스 레벨에 박아둔다. 어플리케이션 레이어 race condition으로 활성 전략이 2개 되거나, 같은 종목에 open trade가 2개 생기는 상황을 DB가 거부한다.
팩터 precompute — incremental upsert
팩터는 매일 시세 적재 직후 자동 계산된다. 핵심은 두 가지: 증분, upsert.
# service/factor/compute.py (요약)
def compute_factors_for_symbol(symbol, incremental=True, last_time=None):
if incremental and last_time is None:
last_time = _last_factor_time(symbol)
if last_time is not None:
# SMA200 연속성 위해 last_time - 300일 부터 로드
cutoff = last_time - timedelta(days=_LOOKBACK_DAYS)
df = _load_ohlcv(symbol, since=cutoff)
else:
df = _load_ohlcv(symbol) # 최초 계산
df = _compute_indicators(df) # RSI, SMA, vol_ratio, ...
out = df[["time", "symbol", *FACTOR_COLUMNS]].dropna(subset=["sma_50"])
if last_time is not None:
out = out[out["time"] > last_time] # 새 봉만
# PK 충돌 시 갱신
stmt = insert(factors_table).values(records).on_conflict_do_update(
index_elements=["time", "symbol"],
set_={c: getattr(stmt.excluded, c) for c in FACTOR_COLUMNS},
)요점:
- 300일 lookback2 — SMA200을 정확하게 계산하려면 마지막 팩터 시점에서 200거래일 + 여유가 필요해서 300 캘린더일을 잡고 들어간다.
on_conflict_do_update(PG upsert) — 같은(time, symbol)이면 갱신, 아니면 insert. 백필 시에도 idempotent3.- 반환값은 upsert된 row 수 — 0이면 새 봉 없음. 호출자가 진행률 표시에 쓴다.
백테스트 엔진 — 포지션 장부
백테스트는 factors + market_data를 읽어 매일 다음 세 단계를 반복한다.
# service/backtest/portfolio.py (요약)
for today_idx, day in enumerate(trading_days):
day_factors = factors_df[factors_df["date"] == day].set_index("symbol")
# 1) Exit 평가 — stop_loss / take_profit / trailing_stop / time_exit / signal_exit
for sym in list(positions.keys()):
reason = _should_exit(pos, today_idx, today_price, day_factors.loc[sym], policy)
if reason:
cash += pos.qty * _net_exit_price(today_price, sym)
del positions[sym]
# 2) 빈 슬롯만큼 신규 진입 (조건 통과 + 미보유 종목)
if empty_slots > 0:
selected = _apply_clauses(day_factors, clauses)
per_slot_cash = cash / empty_slots
for sym, px in selected[:empty_slots]:
qty = per_slot_cash / _net_entry_price(px, sym)
cash -= qty * _net_entry_price(px, sym)
positions[sym] = Position(...)
# 3) 오늘의 총자산 기록
equity_rows.append({"time": day, "value": cash + positions_value})설계 결정 셋:
- 포지션 슬롯 —
max_positions=10같은 자본 분할 슬롯. 빈 슬롯이 있을 때만 신규 진입 → 불필요한 교체 매매 최소화. - 수수료·거래세·슬리피지 반영 — 한국은 매도 시 거래세 0.18%까지 빠지는 게 backtest와 라이브 결과 차이의 가장 큰 원인이라 net price로 명시적으로 분리.
- AND clause 평가 — 룰은
[{factor: "rsi_14", op: "<", value: 30}, ...]의 list._apply_clauses가pd.Seriesmask로 AND 결합한다. JSON으로 직렬화 가능해서 그대로 DB(portfolio_rules.config JSONB) 에 저장.
회고
팩터 precompute로 옮긴 게 가장 효과 컸던 결정. Grid Search 한 회 돌리는 시간이 분 단위에서 초 단위로 떨어졌다. 정확히 같은 코드 베이스로 백테스트와 라이브 스크리닝을 둘 다 돌릴 수 있게 된 게 더 큰 가치이긴 했지만.
작은 lesson:
시계열 데이터에서 “조회 시점”과 “계산 시점”을 분리하면 거의 항상 이긴다.
다음 편은 이 위에서 돌아가는 Grid Search 자동 탐색. 학습 7년 / 검증 3년 양쪽에서 이긴 룰만 추천하는 1차 과적합 필터 얘기.
Footnotes
-
partial unique index —
WHERE절이 붙은 unique 인덱스. 조건을 만족하는 row 사이에서만 unique 제약이 걸린다. “활성 전략은 동시에 1개만” 같은 도메인 제약을 application 레이어가 아니라 DB 가 직접 강제하게 만든다. ↩ -
lookback (윈도우) — 지표 계산을 이어서 하기 위해 과거로 거슬러 받아오는 데이터 기간. SMA200 같은 200일 이동평균은 마지막 시점에서 200거래일 이전부터 다시 로드해야 연속된 값이 나온다. ↩
-
idempotent (멱등) — 같은 입력으로 여러 번 실행해도 결과가 동일한 성질. 백필·재시도가 쉬워진다 — 한 번 실행했는지 추적하지 않아도 안전하게 다시 돌릴 수 있다. ↩